

近日,一村资本投资的端侧AI芯片企业光羽芯辰,在技术和标准制定领域取得新进展。
作为一家成立于2024年的初创企业,光羽芯辰在存算一体、端侧AI芯片领域持续深耕,首颗芯片已实现工程化落地。
其在3D堆叠近存算、SRAM存算、LPU流式处理架构、以及基于RISC-V的AI软件架构四大核心技术方向实现了技术突破。
标准制定方面,光羽芯辰继《端侧AI的3D DRAM芯片集成技术规范》团体标准通过上海集成电路行业协会验收后,再度作为主要起草单位编写《AI算力场景下高带宽存储芯片性能适配技术规范》和《大模型训练用存储芯片高速读写稳定性评价方法》两项团体标准,参与高带宽和AI专用存储芯片的标准制定工作。
3D 堆叠近存算,打通带宽 “高速公路”
针对大模型推理的带宽瓶颈,光羽芯辰开发了基于3D DRAM的近存算架构。该技术通过3D堆叠工艺,将NPU计算核心与DRAM存储阵列进行纵向物理融合,从根本上缩短了数据搬运路径、释放带宽潜力。
配合自研的分布式计算-分布式存储耦合架构、多层次片上网络(NoC)与智能数据分发机制,充分发挥3D堆叠带来的数万级垂直互联通道优势,确保外部高带宽能够转化为计算核心可用的有效吞吐。
SRAM 存算技术,高能效破解推理瓶颈
基于对SRAM存算的工程化研究,光羽芯辰针对VLA模型中计算密集型的矩阵运算,在NPU中集成CIM加速引擎。基于高密度SRAM存算单元实现“存中计算”能力,降低功耗与延迟,提升了端侧AI推理计算的能效比。

光羽芯辰存算技术布局
LPU 流式处理架构,前瞻布局,高效赋能
光羽芯辰在2024年布局LPU流式处理架构研发,目前已在首颗芯片中实现工程化落地。该架构高效支持FFN(前馈神经网络)运算,为端侧大模型的高效推理提供架构支撑。
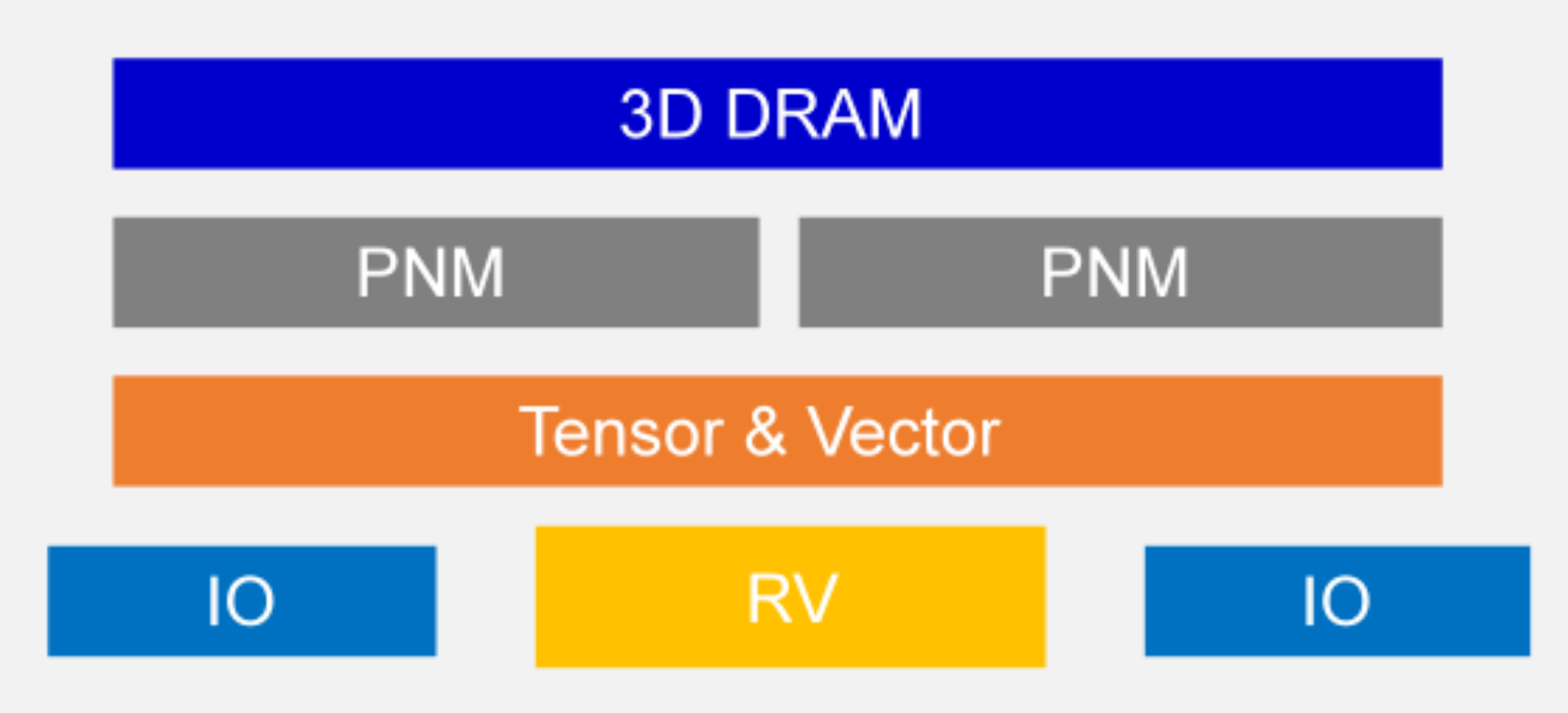
光羽芯辰LPU架构示意图
RISC-V AI 软件架构,轻装上阵,软硬协同
软件生态方面,光羽芯辰基于RISC-V开源指令集架构,打造了一套类CUDA兼容的可编程计算平台。
该架构兼具专用NPU的高效性与通用GPU的灵活性:RISC-V核心负责控制流调度与通用计算任务,NPU专用单元负责矩阵运算等密集型计算,两者通过高速片上总线实现紧耦合通信。这一架构既保留了RISC-V开源开放、可扩展性强的优势,又通过专用加速单元确保了大模型推理的高效性。
从底层架构研发到行业标准参与,从芯片工程化落地到软件生态构建,光羽芯辰持续深耕端侧AI赛道。未来,光羽芯辰将继续在四大核心技术方向进行创新,推动端侧AI技术的发展和应用。
提示:私募基金仅面向与基金风险等级匹配的合格投资者推介或募集。投资有风险,投资者应理性作出投资决策、自行承担投资风险;本公司不作保本保收益或投资无风险的承诺。私募基金产品风险等级评分表详见网站媒体中心页面。
